연구 한눈에 — 무엇을, 어떻게 쟀나 The study at a glance — what we measured, and how
결론의 화려함보다 과정의 투명함이 신뢰를 만듭니다. 이 연구가 실제로 무엇을 측정했는지 먼저 보여드립니다. Trust comes less from a flashy conclusion than from a transparent process. So here is what this study actually measured.
무엇을 들여다봤나 What we examined
주 대상은 Gemma-2-9B(약 92억 개의 파라미터)입니다. 한 대의 소비자용 그래픽카드(RTX 4090, 24GB)에 올리기 위해 4-bit로 압축해 구동했습니다. 결과가 한 모델만의 우연이 아님을 확인하기 위해, 완전히 다르게 학습된 Qwen2.5-7B(28개 층)로 같은 실험을 재현했습니다. The main subject is Gemma-2-9B (about 9.2 billion parameters). To fit it on a single consumer graphics card (RTX 4090, 24GB) we ran it compressed to 4-bit. To check that the results are not a fluke of one model, we reproduced the experiments on a separately trained model, Qwen2.5-7B (28 layers).
얼마나 넓게 봤나 How broadly we looked
인간 뇌 연구가 다루는 기능 영역에 맞춰 23개 영역을 골랐습니다 — 수·코드·논리·인과 / 공포·기쁨·슬픔·분노·혐오 / 마음이론·도덕·공감·얼굴 / 색·맛·음악·운동 / 기억·시간 / 통증·보상 / 언어구문·공간. 각 영역마다 24개의 자극 문장을 넣었고(처음엔 8개였다가 3배로 늘렸습니다), 모델의 42개 층 전부(0~41층)를 살폈습니다. We chose 23 domains, aligned to the functional areas human-brain research studies — number·code·logic·causality / fear·joy·sadness·anger·disgust / theory-of-mind·morality·empathy·face / color·taste·music·motion / memory·time / pain·reward / language-syntax·spatial. Each domain was probed with 24 stimulus sentences (we started at 8 and tripled it), and we examined all 42 layers of the model (layers 0–41).
어떤 좌표계로 그렸나 What coordinate system we drew on
핵심은 '공활성(共活性) 좌표계'입니다. 어떤 자극을 줬을 때 어디가 더 켜지는지를 기록해, 기능이 비슷한 뉴런끼리 가깝게 모아 배치합니다. 이 지도에서의 위치는 물리적 자리가 아니라 기능적 유사도입니다 — 같은 색 덩어리 = 한 기능 집단. The key is a "co-activation" map. We record where the model lights up more for which stimulus, then place neurons with similar function near one another. Position on this map is functional similarity, not a physical location — a same-colored blob is one functional group.
어떤 잣대로 쟀나 What yardsticks we used
- RSA(표상유사성) — 두 영역이 얼마나 같은 반응 패턴을 쓰나. −1(반대)~+1(동일), 0이면 무관. RSA (representational similarity) — how much two domains share the same response pattern. From −1 (opposite) to +1 (identical); 0 means unrelated.
- 2차 RSA — 두 모델의 관계 지도끼리 얼마나 닮았나. (모델 vs 모델 비교라 인간 가정에 의존하지 않습니다.) Second-order RSA — how much two models' relationship maps resemble each other. (A model-vs-model comparison, so it doesn't rely on assumptions about humans.)
- ARI(조정 랜드 지수) — 두 분류(묶음)가 얼마나 겹치나. 1=완전 일치, 0=우연. ARI (adjusted Rand index) — how much two groupings overlap. 1 = perfect, 0 = chance.
- split-half(반분 안정성) — 자극을 반으로 갈라도 같은 지도가 나오나. 1에 가까울수록 견고. Split-half stability — whether the same map emerges when the stimuli are split in two. Closer to 1 means more robust.
꼭 기억할 한 가지. 인간과의 비교에 쓴 '인간 기준'은 실제 fMRI 측정이 아니라 인지·신경과학 문헌에서 유도한 이론적 근사입니다. 그래서 인간 비교의 절대값은 이 근사의 품질에 의존합니다. 반면 모델 대 모델 비교는 그런 가정과 무관해 더 견고합니다. One thing to keep in mind. The "human reference" used for human comparisons is not actual fMRI data but a theoretical approximation derived from cognitive and neuroscience literature. So the absolute values of human comparisons depend on the quality of that approximation. By contrast, model-versus-model comparisons don't rely on those assumptions and are therefore more robust.
F1 · 개념은 '기능 영역'으로 켜진다 F1 · Concepts switch on as "functional regions"
① 무엇을 발견했나. 모델에게 공포와 관련된 문장을 주면, 그에 반응하는 뉴런들이 지도 위에 무작위로 흩어지지 않습니다. 대신 한 덩어리의 연속된 영역으로 켜집니다 — 뇌에서 특정 기능이 특정 영역에 모여 있는 것(fMRI의 기능 영역)과 닮은 모습입니다. 개념의 의미를 담는 단위는 외따로 떨어진 한 뉴런이 아니라, 이웃한 기능 집단이라는 것입니다. ① What we found. When the model is given fear-related sentences, the responding neurons are not scattered randomly across the map. They light up as one continuous region — much as a particular function clusters in a particular brain area (a functional region in fMRI). The unit that carries a concept's meaning is not a lone, isolated neuron but a neighboring functional group.
② 어떻게 알아냈나. 두 가지를 확인했습니다. 첫째, 반분 안정성(split-half): 한 영역의 자극을 반으로 갈라 각각 지도를 그렸을 때 두 지도가 얼마나 같은가를 쟀더니 0.80–0.98로 나왔습니다(1에 가까울수록 같은 지도). 우연이 아니라 재현되는 구조라는 뜻입니다. 둘째, 공간 응집도: 같은 개념을 선호하는 뉴런들이 지도 위에서 실제로 얼마나 뭉쳐 있는지를, 무작위로 흩었을 때와 비교했더니 모든 층에서 우연의 2.4–2.9배 더 뭉쳐 있었습니다. ② How we found it. We checked two things. First, split-half stability: when we split a domain's stimuli in half and drew a map from each, the two maps agreed at 0.80–0.98 (closer to 1 means the same map). That means a reproducible structure, not chance. Second, spatial cohesion: we measured how tightly neurons that prefer the same concept actually cluster on the map, compared with random scattering — they were clustered 2.4–2.9× more than chance, across every layer.
③ 무엇을 조심해야 하나. 이것은 새로운 발견이 아니라 재현입니다. 신경망에서 기능이 국재(局在)한다는 점은 이미 알려져 있고, 우리는 독립적인 좌표계와 측정으로 그것을 다시 확인했을 뿐입니다 — 재현성 위기 시대에 그 자체로 가치가 있지만, '최초'는 아닙니다. 또한 '기능 영역'은 뇌 영역과 닮은 구조이지 같은 것이 아닙니다. 지도 위의 위치는 물리적 자리가 아니라 기능적 유사도라는 점도 기억해 주세요. ③ What to be careful about. This is a replication, not a new discovery. Functional localization in neural networks is already known; we simply confirmed it again with an independent coordinate system and measurement — valuable in an age of a reproducibility crisis, but not a "first." Also, a "functional region" resembles a brain area structurally; it is not the same thing. And remember that position on the map is functional similarity, not a physical location.

F2 · 한 단어를 '3막'으로 처리한다 F2 · It processes a single word in "three acts"
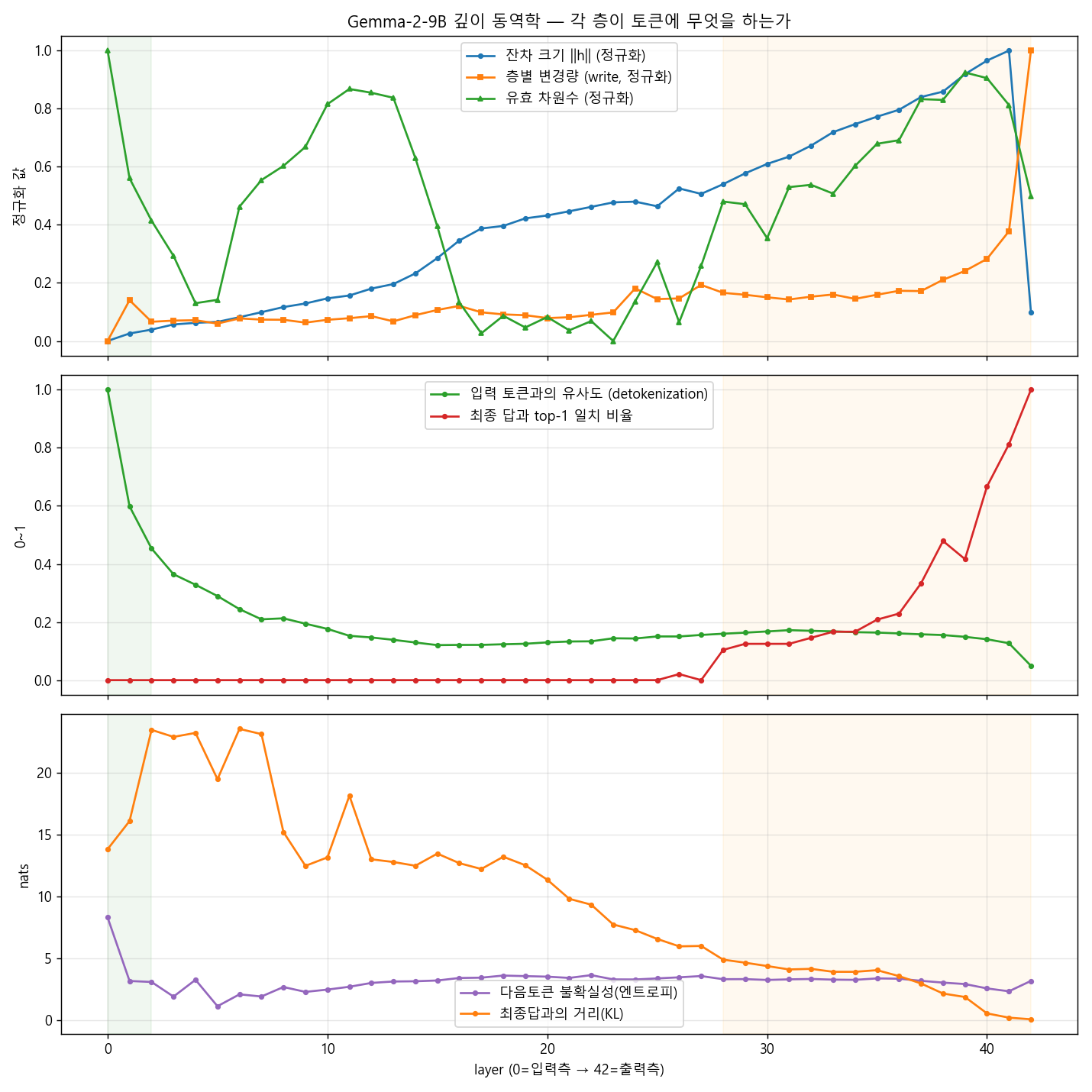
① 무엇을 발견했나. 모델에 한 문장을 넣으면 정보가 42개 층을 차례로 통과합니다. 그 과정은 마치 한 편의 3막극처럼 진행됩니다 — 1막: 글자(토큰) 읽기 → 2막: 의미 만들기 → 3막: 답 쓰기. 흥미로운 점은, 다음에 무슨 단어를 내놓을지가 거의 끝(40번째 층 무렵)에 가서야 정해진다는 것입니다. ① What we found. When a sentence enters the model, the information passes through 42 layers in turn. The process unfolds like a three-act play — Act 1: reading the characters (tokens) → Act 2: building meaning → Act 3: writing the answer. Strikingly, what word to output next is settled only near the very end (around layer 40).
② 어떻게 알아냈나. 한 번의 계산으로 모든 층의 내부 상태를 동시에 들여다보며 여러 잣대로 쟀습니다. ② How we found it. In a single forward pass we inspected the internal state at every layer at once, with several yardsticks.
- 얕은 층(L0–L2)은 아직 입력 단어와 닮아 있습니다. 내부 상태가 입력 토큰과 얼마나 비슷한지를 보면 시작은 1.00이고, 깊어질수록 단조롭게 떨어져 최종 0.05까지 갑니다 — 토큰을 벗어나 맥락의 의미를 입는다는 뜻입니다. Shallow layers (L0–L2) still resemble the input word. Measuring how similar the internal state is to the input token, it starts at 1.00 and falls monotonically to a final 0.05 — meaning it leaves the bare token behind and takes on contextual meaning.
- 깊은 층에서 답이 수렴합니다. 각 깊이에서 "지금 모델이 뭐라고 답할까"를 들여다보는 기법(logit-lens)으로 최종 답과의 거리를 재면 13.84에서 0.10으로 수렴합니다. The answer converges in deep layers. Using a technique (logit-lens) that reads "what would the model answer at this depth," the distance to the final answer falls from 13.84 to 0.10.
- 답은 늦게 결정됩니다. 각 층의 추측이 최종 답과 일치하는 비율이 절반을 넘는 것은 40번째 층(L40)에 가서야입니다. The answer is decided late. The point where each layer's guess matches the final answer more than half the time arrives only at layer 40 (L40).
③ 무엇을 조심해야 하나. 깊이에 따라 처리가 '단계'를 이룬다는 사실 자체는 이미 학계의 정설입니다 — Lad·Gurnee·Tegmark(2024)의 'Stages of Inference', 그리고 logit-lens·tuned-lens 연구들. 따라서 우리의 기여는 '단계 발견'이 아니라, 그 단계들을 우리 개념 좌표계로 시각화하고 이 모델에서 답이 L40에서야 결정된다는 늦은 결정 시점을 정량화한 것입니다. 한 번 더 강조하면 — 모델은 '생각'하거나 '의도'하지 않습니다. 이것은 정보가 층을 통과하며 변형되는 과정의 측정입니다. ③ What to be careful about. That depth-wise processing forms "stages" is already established in the literature — Lad·Gurnee·Tegmark (2024) "Stages of Inference," plus logit-lens and tuned-lens work. Our contribution is therefore not "discovering stages" but visualizing them in our concept coordinate system and quantifying, in this model, the late decision point at L40. And to repeat — the model does not "think" or "intend." This is a measurement of how information is transformed as it passes through layers.
F3 · 서로 다른 AI는 거의 똑같이 수렴한다 — 인간과는 부분적으로만 F3 · Different AIs converge almost identically — humans only partly
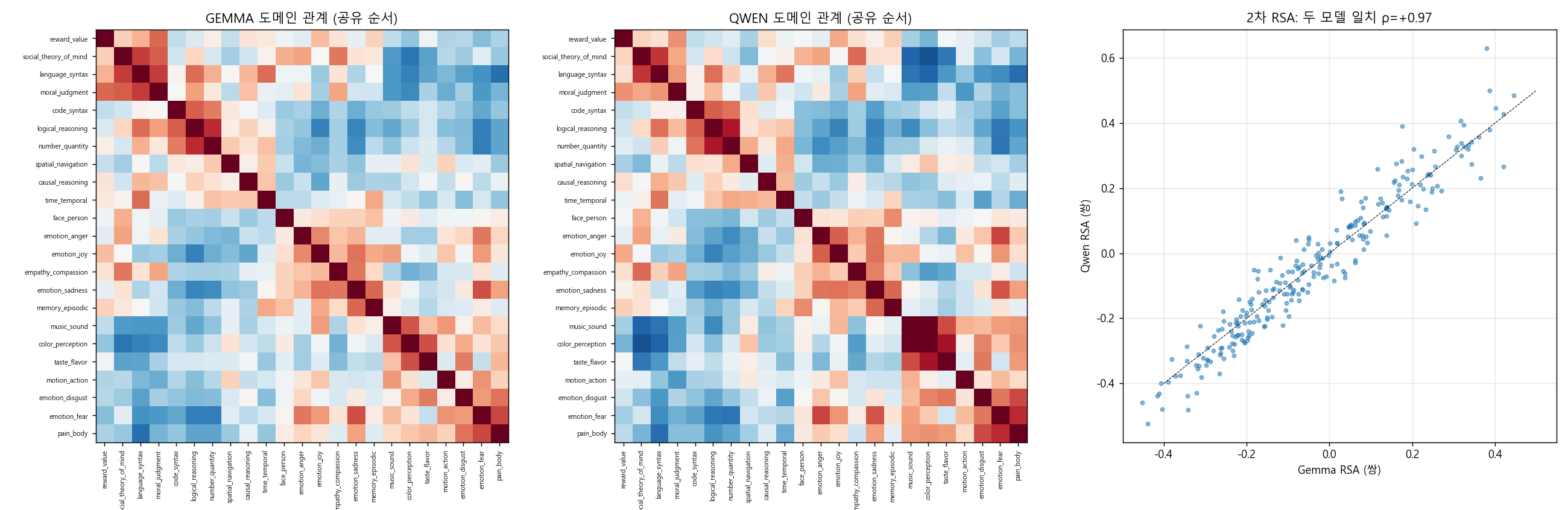
① 무엇을 발견했나. 이번 라운드에서 가장 또렷하고 새로운 결과입니다. 완전히 다르게 학습된 두 AI — Gemma와 Qwen — 에게 23개 영역을 물었더니, 영역들 사이의 관계 지도가 거의 판박이로 나왔습니다. 그런데 그 둘이 함께 그려낸 '공통의 모양'은, 인간 뇌가 영역을 묶는 방식과는 부분적으로만 닮았습니다. 즉 텍스트만으로 수렴하는 공통 표상은 분명히 존재하지만(서로 다른 AI가 같은 곳으로 모인다), 그 수렴점이 인간이라는 보장은 없습니다. ① What we found. This is the sharpest and most novel result of the round. When we asked two very differently trained AIs — Gemma and Qwen — about 23 domains, the relationship maps among those domains came out nearly identical. Yet the "shared shape" the two of them draw resembles how the human brain groups areas only partly. So a common representation that converges from text alone clearly exists (different AIs gather at the same place) — but there is no guarantee that the meeting point is humans.
② 어떻게 알아냈나. 두 모델 각각에서 23×23 관계 행렬(어떤 영역끼리 같은 패턴을 쓰나)을 만든 뒤, 행렬끼리 비교했습니다. ② How we found it. From each model we built a 23×23 relationship matrix (which domains use the same pattern), then compared the matrices.
- 두 모델의 관계 지도 일치(2차 RSA) = +0.97. 거의 모든 관계 쌍이 두 모델에서 같은 값으로 정렬됐습니다. 양의 관계(예: 수↔논리)뿐 아니라 음의 관계까지 똑같이 재현됐습니다(공포↔사회 −0.07/−0.11, 통증↔보상 −0.19/−0.16). Agreement of the two models' relationship maps (second-order RSA) = +0.97. Nearly every relationship pair lined up to the same value in both models. Not only positive relations (e.g. number↔logic) but even negative ones were reproduced identically (fear↔social −0.07/−0.11, pain↔reward −0.19/−0.16).
- 두 모델의 묶음 일치(ARI) = +0.61 — 같은 가족으로 묶었습니다. Agreement of the two models' groupings (ARI) = +0.61 — they form the same families.
- 반면 LLM과 인간 뇌 가족의 일치(ARI)는 약 +0.30(Gemma +0.29, Qwen +0.31). 양수이니 우연 이상으로 닮긴 했지만, 두 모델끼리의 0.97과는 큰 차이입니다. By contrast, agreement between the LLM and human brain families (ARI) is about +0.30 (Gemma +0.29, Qwen +0.31). Positive, so more than chance — but far below the 0.97 between the two models.
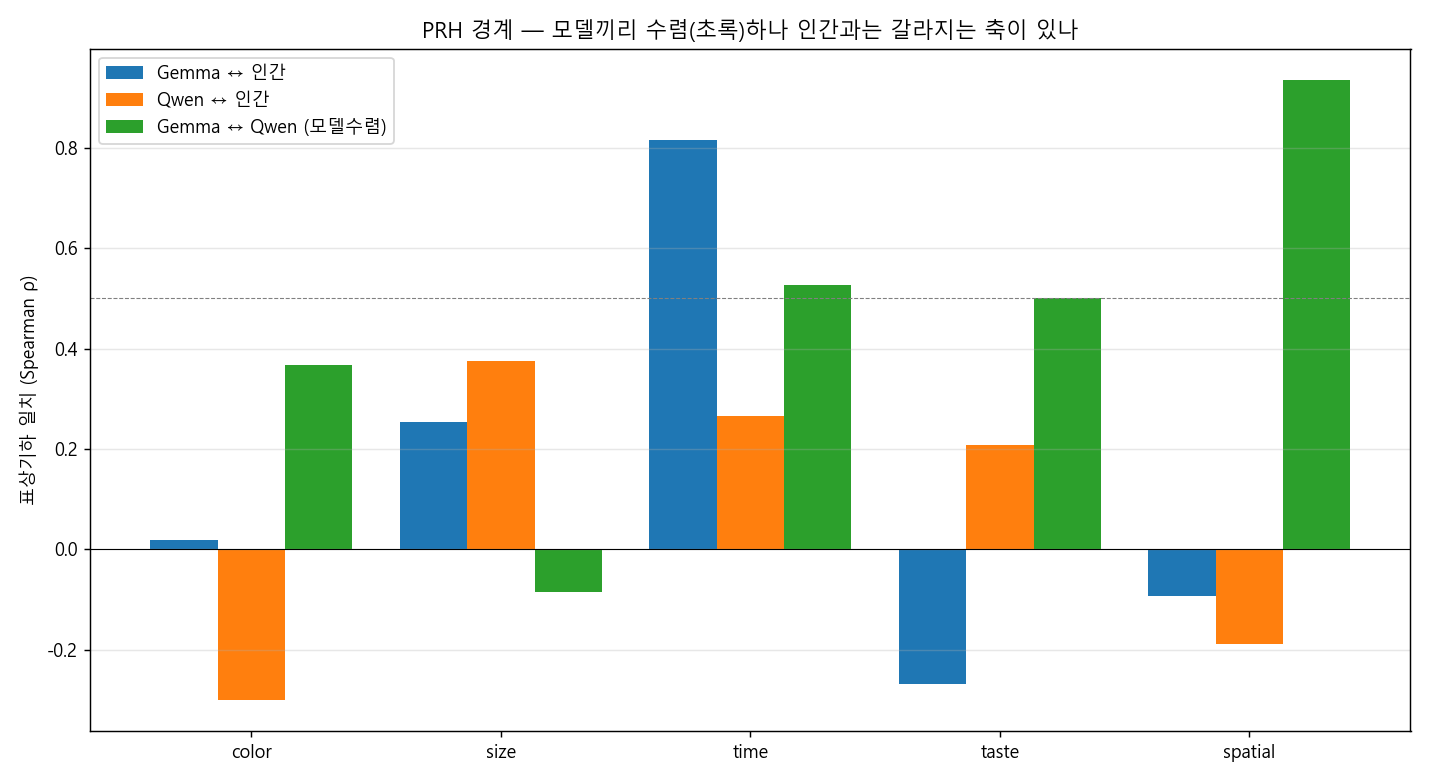
경계가 가장 선명한 곳 — 공간(spatial)과 맛(taste). 방향·공간 축에서 두 모델은 +0.94로 거의 동일하게 수렴하지만 인간 기준과는 −0.14로 무관합니다. 맛도 같은 패턴(모델끼리 +0.50, 인간과 −0.03). 두 독립 AI가 같은 곳으로 모이는데, 그곳이 인간이 아닌 대표적인 축입니다. Where the boundary is sharpest — spatial and taste. On the directional/spatial axis the two models converge almost identically at +0.94, yet are unrelated to the human reference at −0.14. Taste shows the same pattern (models +0.50, humans −0.03). Two independent AIs gather at the same place, and that place is conspicuously not human.
③ 무엇을 조심해야 하나. 인간과의 비교(ARI ~0.30)에 쓴 인간 기준은 실측 fMRI가 아니라 문헌에서 유도한 이론적 근사입니다. 그래서 이 절대값은 근사의 품질에 의존합니다. 다만 모델 대 모델 비교(0.97)는 그런 가정과 무관하므로 훨씬 견고합니다 — 이것이 이 결과의 핵심 힘입니다. 또 한 가지: 인간 일치 수치는 더 정직한 추정으로 내려갔습니다. 자극이 8개였을 때는 0.57로 꽤 높아 보였지만, 24개로 늘리자 0.30으로 떨어졌습니다(작은 표본에서 우연히 더 맞아 보였던 것). 마지막으로, 이 수렴은 두 모델(Gemma·Qwen)에서 확인됐을 뿐이며, '모든 AI'를 말하려면 제3의 계열(예: Llama)이 더 필요합니다. ③ What to be careful about. The human reference used for the human comparison (ARI ~0.30) is a theoretical approximation derived from literature, not measured fMRI. Its absolute value therefore depends on the quality of that approximation. But the model-vs-model comparison (0.97) doesn't rely on those assumptions and is far more robust — that is the core strength here. One more thing: the human-agreement figure was revised down to a more honest estimate. With 8 stimuli it looked fairly high at 0.57, but tripling to 24 dropped it to 0.30 (small samples happened to match better by chance). Finally, this convergence was confirmed in only two models (Gemma, Qwen); claiming "all AIs" would need a third family (e.g. Llama).
F4 · 인간을 닮은 정도는 '축'마다 다르게 갈라진다 F4 · How human-like it is varies by "axis"
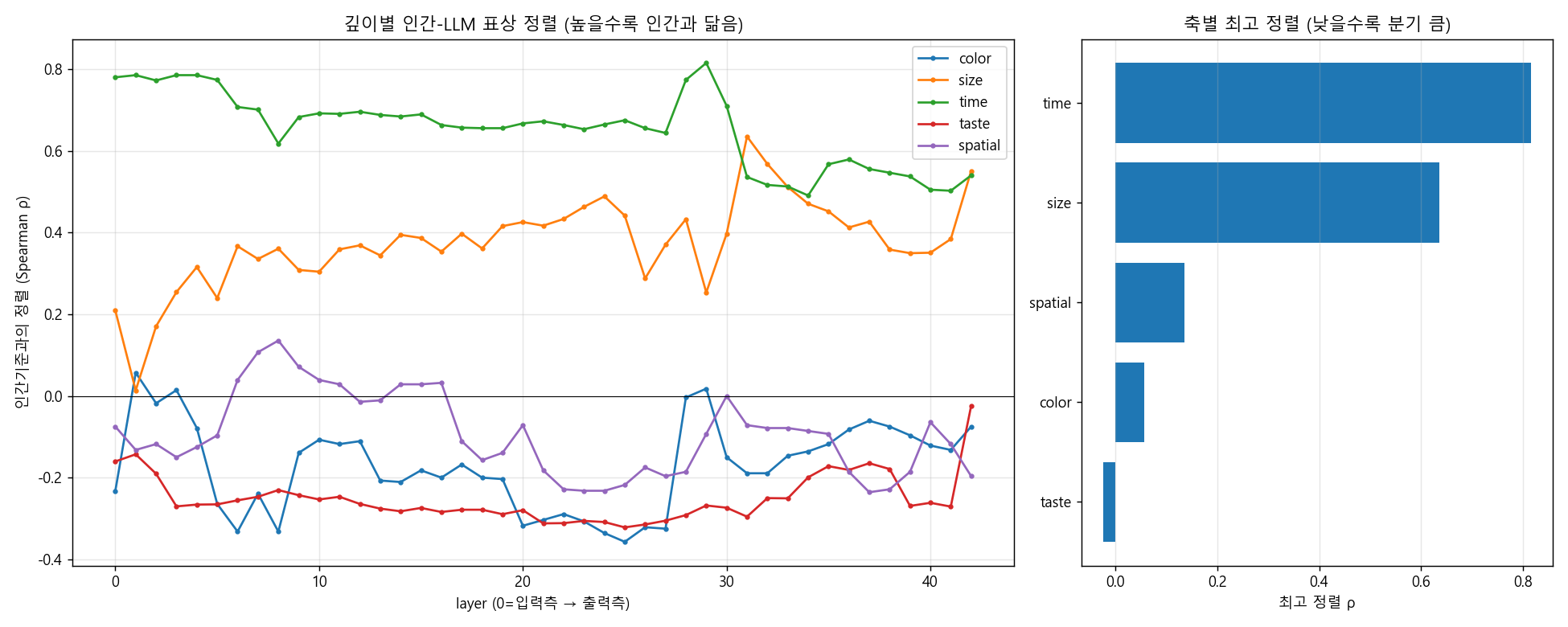
① 무엇을 발견했나. 텍스트만 배운 LLM은 어떤 개념은 인간과 닮게, 어떤 건 거의 무관하게 배웠습니다. 대체로 텍스트에 잘 담기는 축(시간·크기)은 인간과 닮게, 몸으로 느껴야 아는 축(맛)은 거의 무관하게 갈라졌습니다. 그 안에서 숫자는 특별한데, 깊이에 따라 표상의 모양 자체가 바뀝니다. ① What we found. An LLM trained only on text learned some concepts to resemble humans and others to be nearly unrelated. Broadly, axes that text captures well (time, size) came out human-like, while an axis you must feel through the body (taste) came out nearly unrelated. Within this, number is special: the very shape of its representation changes with depth.
② 어떻게 알아냈나. 다섯 개 축마다 항목들(예: 색=빨강…보라, 맛=단맛…쓴맛)을 모델에 넣어 항목 간 거리 지도를 만들고, 인간 인지가 예측하는 거리 지도와 얼마나 닮았는지(정렬 ρ, 1에 가까우면 닮음, 0이면 무관)를 쟀습니다. 분기가 큰 순서(작을수록 인간과 다름)는 이렇게 나왔습니다. ② How we found it. For each of five axes we fed the model the items (e.g. color = red…purple, taste = sweet…bitter), built an item-to-item distance map, and measured how much it resembled the distance map predicted by human cognition (alignment ρ; near 1 = alike, 0 = unrelated). Ranked by divergence (smaller = less human-like):
맛 −0.02 < 색 0.06 < 공간 0.14 ≪ 크기 0.64 < 시간 0.82 taste −0.02 < color 0.06 < spatial 0.14 ≪ size 0.64 < time 0.82
가장 정렬이 좋은 깊이는 중후기 층(L29–L31)으로, 이전 발견('중후기 층이 가장 뇌같은 기하')과 독립적으로 일치합니다. Alignment peaked in mid-to-late layers (L29–L31), independently matching an earlier finding ("mid-to-late layers carry the most brain-like geometry").
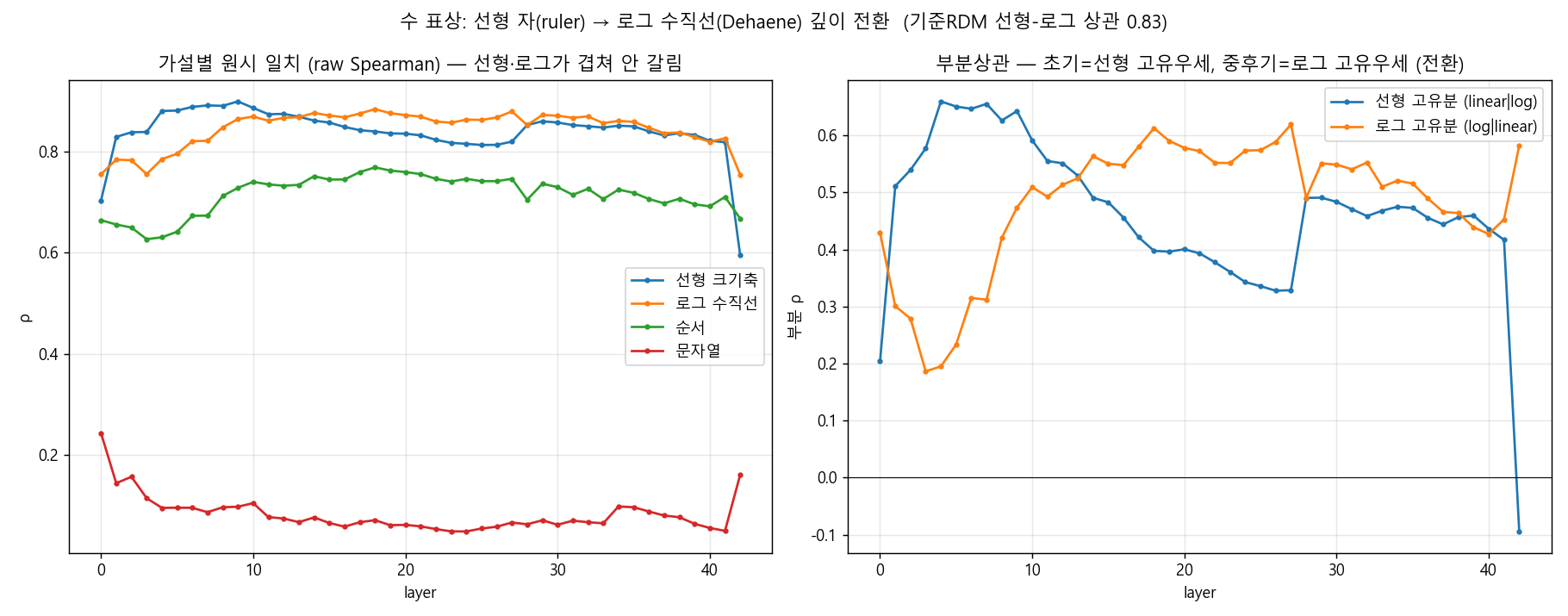
숫자의 기하 전환. 학계에서 두 논문이 충돌해 왔습니다 — LLM이 수를 선형 크기축(자처럼 일정 간격)으로 두느냐, 로그 수직선(인간의 심적 수직선처럼 큰 수일수록 촘촘)으로 두느냐. 우리 데이터는 깊이에 따라 둘이 바뀐다고 답합니다: 얕은 층(L2–12)에선 선형이, 중후기 층(L18–42)에선 로그 수직선이 우세하고, 교차점은 대략 L12–18입니다. 선형 지도와 로그 지도는 서로 0.83으로 강하게 얽혀 있어 원시 비교로는 못 가르므로, 부분상관(한쪽을 통제하고 다른쪽의 고유 설명력만 보기)으로 갈라냈습니다. 충돌하던 두 논문이 서로 다른 깊이를 본 것일 수 있다는, 화해의 가능성입니다. The number-geometry switch. Two papers in the literature have clashed — does an LLM place numbers on a linear magnitude axis (evenly spaced like a ruler), or on a logarithmic number line (denser at larger numbers, like the human mental number line)? Our data answers that the two swap with depth: linear dominates in shallow layers (L2–12), the logarithmic number line in mid-to-late layers (L18–42), crossing over around L12–18. Because the linear and log maps are themselves strongly entangled (0.83), a raw comparison can't separate them, so we used partial correlation (controlling for one and reading only the other's unique explanatory power). It raises the possibility that the two clashing papers were each looking at a different depth — a reconciliation.
③ 무엇을 조심해야 하나. 수가 갈라진다는 것 자체는 '세계 최초'가 아니라 학계에서 논쟁 중(contested)입니다 — LLM이 수를 로그 수직선(arXiv:2502.16147)이나 선형 부분공간(arXiv:2401.03735)으로 부호화한다는 경쟁·반례 결과가 있습니다. 우리가 새로 더한 것은 '수가 다르다'가 아니라 '깊이에 따라 선형→로그로 전환한다'는 화해와, 단일 일화를 5축으로 일반화·통제한 점입니다. 또 인간 기준 지도는 실측 fMRI가 아니라 이론 prior이며, 항목 수가 6~8개로 작아 탐색적입니다. 예측의 긴장도 정직히 둡니다 — '선형 토큰이 요일의 순환성을 깰 것'이란 예상과 달리 시간이 가장 정렬됐고, 색은 선행연구(Abdou 2021)의 주장보다 낮게 나왔습니다. ③ What to be careful about. That numbers diverge is not a "world first" but an open, contested question — there are competing/counter results that an LLM encodes numbers as a log number line (arXiv:2502.16147) or a linear subspace (arXiv:2401.03735). What we add is not "numbers are different" but the reconciliation that it switches linear→log with depth, plus generalizing and controlling a single anecdote across five axes. Also, the human reference maps are a theoretical prior, not measured fMRI, and with only 6–8 items per axis they are exploratory. We keep the tensions honest, too — against the prediction that "linear tokens would break the cyclicity of weekdays," time aligned best, and color came out lower than a prior claim (Abdou 2021).
F5 · 정직한 자기수정 — 옛 간판 주장을 우리 손으로 바로잡다 F5 · An honest self-correction — fixing our own headline claim
① 무엇을 발견했나. 이전 5개 개념 연구에서 우리는 공포↔사회추론의 결합이 가장 강한 묶음이라고 보고했습니다(표상유사도 0.52→0.57). 그런데 영역을 23개로 넓히고 모든 개념이 공유하는 공통 성분을 제거하니, 그 강한 결합이 사실상 사라졌습니다. 좋은 과학은 스스로를 수정합니다. 이 섹션은 그 사례입니다. ① What we found. In an earlier study of five concepts, we reported that the fear↔social-reasoning coupling was the strongest grouping (representational similarity 0.52→0.57). But once we widened to 23 domains and removed a component shared by all concepts, that strong coupling essentially vanished. Good science corrects itself. This section is one such case.
② 어떻게 알아냈나. 핵심은 공통 성분 제거입니다. 자극으로 쓴 공포 문장과 사회 문장은 둘 다 '감정적으로 무거운 문장'이라는 공통점(공통 각성 성분)을 갖습니다. 모든 개념이 공유하는 이 성분을 빼고 영역 고유의 관계만 다시 측정하자, 공포↔사회 표상유사도는 −0.07(Gemma) / −0.11(Qwen) — 사실상 0이거나 약한 음수로 떨어졌습니다. 이 수정은 자극을 3배(8→24)로 늘리고 독립 모델 두 곳에서 모두 같게 나와 견고합니다. 제대로 통제하면 공포는 다른 감정들과, 사회추론은 도덕·언어와 각각 다른 가족으로 묶입니다. ② How we found it. The key is removing a common component. The fear and social stimuli we used both share a trait — being "emotionally weighty sentences" (a common arousal component). When we subtracted this shared component and remeasured only each domain's unique relationships, the fear↔social similarity fell to −0.07 (Gemma) / −0.11 (Qwen) — effectively zero, or a weak negative. This correction is robust: it came out the same after tripling the stimuli (8→24) and across both independent models. Properly controlled, fear groups with other emotions, and social reasoning with morality and language — different families.
③ 무엇을 조심해야 하나 — 그리고 무엇이 살아남았나. 이것을 '능동적 억제'나 '차단·비활성화'로 읽으면 안 됩니다. 우리가 측정한 것은 표상 유사도(상관)가 약하다는 것이지, 한쪽이 다른쪽을 끈다는 것이 아닙니다. 원래의 강한 결합은 상당 부분 두 자극이 공유한 공통 각성 성분 때문이었습니다. (참고로 인과 조종(steering) 실험은 별개의 측정이며 그 결과(+0.36)는 여전히 유효합니다 — 표상 유사도가 약하다는 것과는 다른 차원의 이야기입니다.) ③ What to be careful about — and what survived. This must not be read as "active suppression" or "blocking / deactivation." What we measured is that representational similarity (correlation) is weak, not that one shuts the other off. The original strong coupling was largely due to the common arousal component the two stimuli shared. (For reference, the causal steering experiment is a separate measurement and its result (+0.36) still holds — a different dimension from representational similarity being weak.)
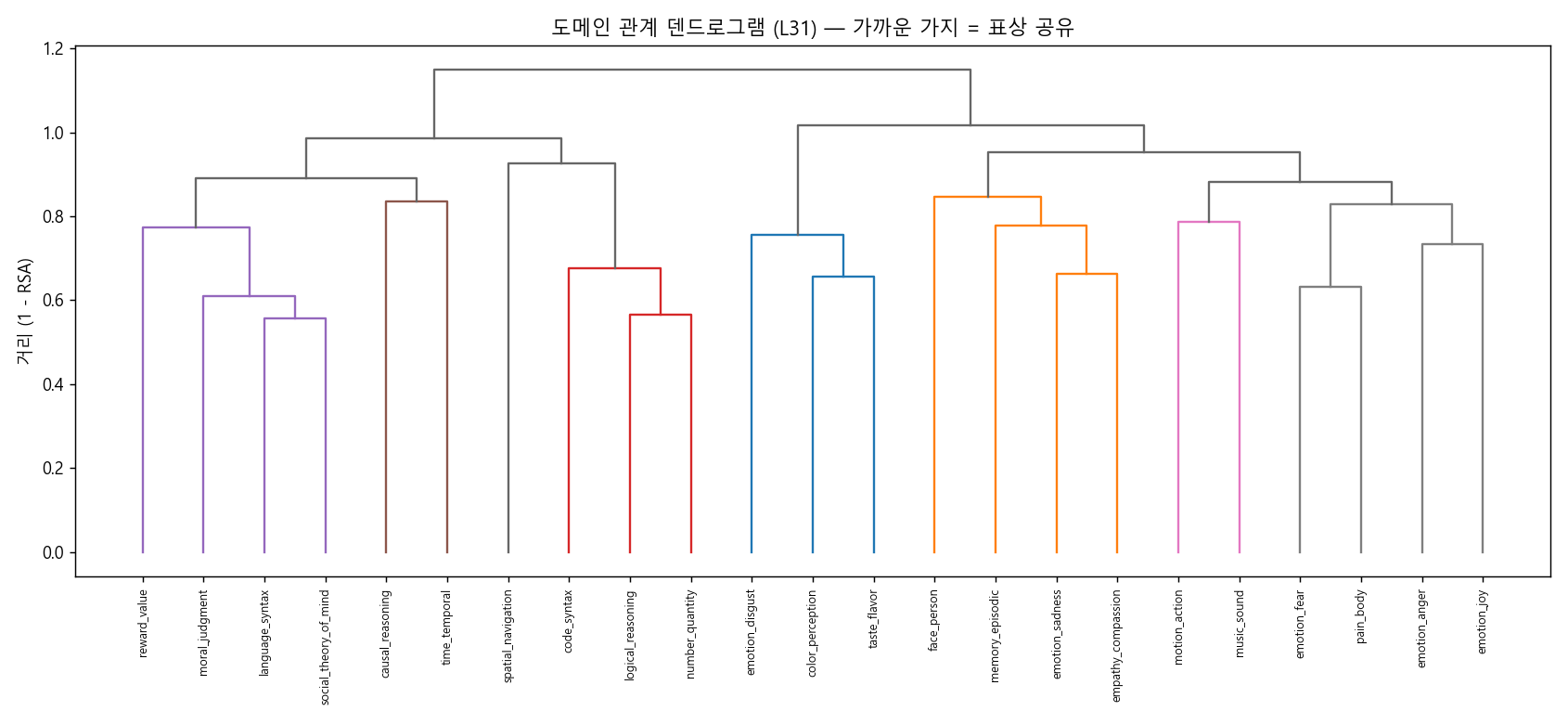
한편 흔들리지 않고 살아남은 것들도 분명합니다. 자극을 3배로 늘리고 두 모델에서 확인해도 단단했던 안정 가족이 있습니다 — 기호 추론(수·코드·논리), 사회-가치-언어(마음이론·도덕·보상·구문), 체화의 다리(혐오↔미각↔색), 운동↔음악, 기억↔시간. 특히 공간(spatial)은 자극을 늘려도 견고하게 독립적입니다. 우리는 무너진 주장과 살아남은 주장을 똑같이 정직하게 보고합니다. Meanwhile, plenty stood firm. There are stable families that held up after tripling the stimuli and across both models — symbolic reasoning (number·code·logic), social-value-language (theory-of-mind·morality·reward·syntax), embodied bridges (disgust↔taste↔color), motion↔music, memory↔time. In particular, spatial stays robustly independent even as stimuli grow. We report the claims that collapsed and the claims that survived with equal honesty.
한계와 정직한 결론 Limits and an honest conclusion
이 연구가 말할 수 없는 것을 분명히 해 둡니다. 한계를 숨기지 않는 것도 과학의 일부입니다. Let us be clear about what this study cannot say. Not hiding the limits is part of science, too.
- 인간 기준은 실측이 아니라 이론 prior입니다. 인간과의 모든 비교(ARI, 정렬 ρ)는 실제 fMRI 데이터가 아니라 인지·신경과학 문헌에서 유도한 가설적 참조 지도와의 비교입니다. 그 절대값은 이 근사의 품질에 의존합니다. 반대로, 모델 대 모델 비교(2차 RSA +0.97)는 이 가정과 무관해 더 견고합니다. The human reference is a theoretical prior, not a measurement. Every human comparison (ARI, alignment ρ) is against a hypothetical reference map derived from cognitive and neuroscience literature — not real fMRI data. Its absolute value depends on the quality of that approximation. By contrast, the model-vs-model comparison (second-order RSA +0.97) is independent of these assumptions and more robust.
- 모델은 두 개뿐입니다. 수렴(0.97)은 Gemma·Qwen에서 확인됐습니다. '모든 AI가 그렇다'고 말하려면 제3의 계열(예: Llama)에서 재현이 필요합니다. There are only two models. The convergence (0.97) was confirmed in Gemma and Qwen. Claiming "all AIs do this" needs replication in a third family (e.g. Llama).
- 수의 분기는 논쟁 중(contested)입니다. '세계 최초'가 아니라, 반례 논문(arXiv:2502.16147, 2401.03735)이 존재하는 열린 문제입니다. 우리가 더한 것은 '깊이에 따른 선형→로그 전환'이라는 화해입니다. The number divergence is contested. It is not a "world first" but an open question with counter-results (arXiv:2502.16147, 2401.03735). What we add is the reconciliation of a linear→log switch with depth.
- RSA는 방법에 민감합니다. 표상유사도의 부호·크기는 baseline·centering(공통 성분 제거) 선택에 따라 크게 달라집니다 — F5의 자기수정이 바로 이 점을 직접 보여줍니다. RSA is method-sensitive. The sign and size of representational similarity shift substantially with baseline and centering (common-component removal) choices — the self-correction in F5 demonstrates exactly this.
- 유비이지 동일이 아닙니다. LLM의 '기능 영역'은 뇌 영역과 닮은 구조이지 같은 것이 아닙니다. 모델은 느끼거나 의도하지 않습니다. It is analogy, not identity. An LLM's "functional region" resembles a brain area structurally; it is not the same. The model does not feel or intend.
- 아직 미결인 것들. 색(color)의 낮은 정렬이 측정 방식 탓인지 진짜 약한 그라운딩 탓인지는 부분적으로만 갈렸고('약그라운딩' 쪽이 대체로 유지), 개념별 내재차원의 깊이 법칙은 현재 측정으로는 결론을 못 냈습니다(미결). Still unresolved. Whether color's low alignment is due to measurement or genuinely weak grounding was only partly settled (the "weak grounding" reading mostly held), and a depth law for per-concept intrinsic dimension could not be decided with current measurements (open).
정직한 한 줄. 이 연구가 강하게 말할 수 있는 것은 모델 사이의 수렴입니다 — 서로 다른 AI가 개념 관계를 거의 똑같이 조직한다는 것. 그 공통 구조가 인간과 어디까지 닮았는지는, 더 많은 모델과 실제 뇌 데이터로 이어서 풀어야 할 다음 과제입니다. An honest one-liner. What this study can say strongly is the convergence among models — that different AIs organize concept relationships almost identically. How far that shared structure resembles humans is the next task, to be worked out with more models and real brain data.
출처와 데이터 Sources and data
이 사이트의 모든 수치는 아래 선행연구와 우리 산출물에 근거합니다. 인간과의 비교에 쓴 인간 기준은 실측 fMRI가 아니라 이 문헌들에서 유도한 이론적 근사임을 다시 밝힙니다. Every figure on this site rests on the prior work and our outputs below. Again: the human reference used for human comparisons is a theoretical approximation derived from this literature, not measured fMRI.
처리 단계·깊이 동역학 (F2) Processing stages / depth dynamics (F2)
- Lad, Gurnee, Tegmark (2024) — The Remarkable Robustness of LLMs / Stages of Inference
- nostalgebraist — logit lens; Belrose et al. (2023) — Tuned Lens (arXiv:2303.08112)
- Tenney et al. (2019) — BERT의 층별 언어 위계 (arXiv:1905.05950); Gurnee & Nanda (2023) (arXiv:2305.01610); DiCarlo & Cox (2007) — untanglingTenney et al. (2019) — layerwise linguistic hierarchy (arXiv:1905.05950); Gurnee & Nanda (2023) (arXiv:2305.01610); DiCarlo & Cox (2007) — untangling
모델 수렴 (F3) Model convergence (F3)
- Huh, Cheung, Wang, Isola (2024) — Platonic Representation Hypothesis (arXiv:2405.07987)
- Kriegeskorte et al. (2008) — Representational Similarity Analysis
수의 기하 (F4, contested) Number geometry (F4, contested)
- arXiv:2502.16147 — LLM의 로그 수직선 부호화arXiv:2502.16147 — log number-line encoding in LLMs
- arXiv:2401.03735 — LLM의 선형 부분공간 부호화arXiv:2401.03735 — linear-subspace encoding in LLMs
- Hubbard et al. (2005) — 인간 두정엽의 수-공간 표상Hubbard et al. (2005) — number-space representation in the human parietal cortex
그라운딩·감각 축 (F4) Grounding / sensory axes (F4)
- Xu (2025) — Nature Human Behaviour (텍스트-only 모델의 감각 축 분기)Xu (2025) — Nature Human Behaviour (sensory-axis divergence in text-only models)
- Abdou et al. (2021) — 언어모델의 색 구조 부호화Abdou et al. (2021) — color-structure encoding in language models
중첩·기능 표상 (배경) Superposition / functional representation (background)
- Elhage et al. (2022) — Toy Models of Superposition; Li…Tegmark (2024) (arXiv:2410.19750)
- Zou (2023) RepE; Turner (2023) ActAdd; Rimsky (2023) CAA (인과 steering)Zou (2023) RepE; Turner (2023) ActAdd; Rimsky (2023) CAA (causal steering)
데이터·스크립트 위치 Data and scripts
(/Users/neibc/dev/llmvisualizationresearch/ 기준)
(relative to /Users/neibc/dev/llmvisualizationresearch/)
-
종합 보고서: Synthesis reports:
out/CORE_FINDINGS.md,out/FINDINGS_EXT.md,out/OPEN_QUESTIONS.md,out/DOMAIN_ATLAS.md,out/DOMAIN_UNIVERSALITY.md -
그림: Figures:
out/ATLAS_parcellation_alllayers.png,out/LAYERDYN_profile.png,out/DOMAIN_crossmodel.png,out/PRH_boundary.png,out/DIVERGENCE_profile.png,out/NUMBERGEOM_partial.png,out/DOMAIN_dendrogram.png -
단계별 분석·원자료: Stage analyses / raw:
_workspace/analysis/STAGE*.md,out/stage*.npz